Are AI Generated Works Copyrightable? I and ChatGPT Give Different Answers
With much attention drawn to ChatGPT, people are interested in discussing whether AI generatedworks are copyrightable. When I am asked this kind of question, my answer is basically no.However, when I asked ChatGPT, the most well-known AI program, it answered yes. Open AI,ChatGPT developer claimed that it was entitled to benefits from these works. I would like todiscuss this issue with you.
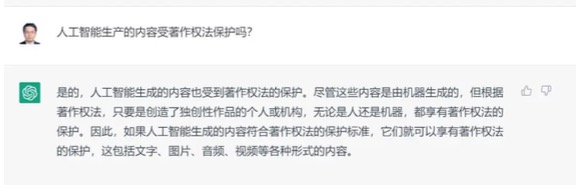
(Original Record A of Communications with ChatGPT)

(Translation of Original Record A)

(Original Record B of Communications with ChatGPT)

(Translation of Original Record B)
First, my argument is that no person should be granted copyright in or paid a license fee for AIgenerated works because they are not copyrightable in nature. Users can claim their rights underthe Anti-Unfair Competition Law in case of AI generated work infringement.
I. Origianl sin of copyrighting AI
The fundamental problem in charging royalties for AI is AI itself. Charging royalties for AI is illogical because its training process is illegal, involving extensive infringement.
ChatGPT and other similar AI developers are bound to use large quantities of data and resourcesto teach and train AI. Major AI companies are secretive about learning resources. Some treatthem as trade secrets. The biggest problem is that the most popular AI products are trained withfree open online data and resources crawled by developers. They feed and train AI with such dataand resources without consent of crawled websites. There is an action arising from this greatdispute brought by media.
When I ask ChatGPT, the answer is training data are open online data that are not and do notneed to be licensed.

(Original Record C of Communications with ChatGPT)

(Translation of Original Record C)
I consider that the data crawling might involve infringement. Is the data crawling an illegal activity?Many internet users think it depends on Robots Agreement. It is legal for search engines to crawl data on websites that agree to be crawled under its Robots Agreement. As AI companies andsearch engines do not crawl data for the same purpose, it is very controversial whether theactivity of AI companies crawling data is governed by Robots Agreement.
Website visits incur costs of server, technical maintenance and management. Website ownersallow search engines to crawl them because both sides can benefit from it. Search engines give aguide to website visits for search engine users by data crawling which helps crawled websites inbusiness by facilitating website visits.
On the contrary, AI companies crawl data only to train their AI programs in their own interests,leaving nothing to website owners that pay server, technical maintenance and management costs.This activity should be governed by Copyright Law, not Robots Agreement.
In Copyright Law, the process of AI learning online content is reproduction or temporaryreproduction. AI companies crawl online or offline content and import it into an AI program.Reproducing content, including words, pictures, audio recordings, videos and programs shouldbe subject to related owner license. Unauthorized reproduction might involve infringement.
A very small possibility is that the activity of AI learning online content might be temporaryproduction, which means data are deleted once learned by AI. In China, temporary reproductiondoes not require copyright owner license but might be questioned as to whether data sourcesare open and can be crawled or it is legal to make offline data (such as books and literature) intoelectronic copies. According to search results generated by ChatGPT in Microsoft New Bing, thecontent generated with links for reference showed ChatGPT was very likely to store the websitecontent. This is not temporary reproduction.
Some websites abide by open agreements, under which people can freely copy and re-publishthe content of these websites, provided that they do not violate the open agreement, for example,Wikipedia’s GNU free file permit. AI companies could crawl content on such websites andrepublish it with a mark showing the source. OpenAi published ChatGPT generated content on itswebsite without giving users a link to the source of data, while Microsoft New Bing publishedChatGPT generated content with a link to the source. Despite differences between ChatGPT generated content and Wikipedia, such selfish activities will gradually undermine the open sourceculture. If Wikipedia brings an action in China, I believe that they could claim that OpenAI’scrawling violate generally accepted business ethics by referring to Article 2 of Unfair CompetitionLaw, besides Copyright Law.
II. Why AI generated works are not copyrightable?
Berne Conventionon the Protection of Literary and Artistic Works dated 9 September 1886formulated in Berne, Switzerland is a globally recognized copyright convention, to which China isa member. Article 1 thereof explicitly states that each party to the convention should protectauthor’s rights in literary and artistic works. In Article 3 thereof, authors include citizens ofcountries that are or aren’t parties thereto. So authors must be natural people. ChatGPT andother AI software could not have been authors in copyright. That is the reason why no copyrightregistration authority in any country has accepted AI as an author.
In Chinese Copyright Law, in addition to natural people, legal people can also be the owner ofworks. ChatGPT created works are not legal person’s works. Legal person’s works are created bynatural people and comprised of the following elements.
1. The work should be conducted by a legal person or other type of organization;
2. The work should represent the will of a legal person or other type of organization; and
3. A legal person or other type of organization should be responsible for the work.
If I ask ChatGPT to write an article, I conduct the work and ChatGPT creates the work at my will.If the article infringe other person’s rights, I should be responsible for the infringement. There isnothing to do with ChatGPT. Therefore, the article written by ChatGPT is not a legal person’s work.I just give some conditions to generate the article, not creating it and should not own copyrightin it.
Work creation by AI is like a commission. The commissioning party gives instructions upon whichAI finishes the work. The AI program is real creator of the work. In Copyright Law, in general,copyright in a commissioned work is owned by the commissioned party. This is the basis on which staff of an AI company told me they owned copyrights in AI generated works.
Despite what they said, ChatGPT is rational when preparing legal instruments. Article 4.2 of theUser Agreement provides that intellectual property rights in any content generated by the userusing ChatGPT is owned by the user, provided that ChatGPT may use such content without payingto the user. I understand that if ChatGPT claimed it owned intellectual property rights in the works,users would be unsatisfied and ChatGPT, the intellectual property owner would be responsiblefor the content when having intellectual property rights in the same, in which case if the contentinfringes other person’s rights or is disputed, such as copyright or reputation infringement oreven worse, politically improper speeches, Open AI, a startup company might not be able to dealwith it.
III. What if a work created by a person using AI is misused by other person?
As AI generated works are not protected by Copyright Law, if a work created by a person using AIis misused, how could that person protect their rights in the misused work?
First, look at a precedent case. A computer software called Dreamwriter developed by Tencentcould write articles on its own and generate three hundred thousand articles a year. Tencentbrought an infringement action against a website that re-published an AI generated articles onthe website of Tencent securities. The court of Nanshan District held that the articles weretechnically generated by Dreamwriter software, met the conditions for protection of writtenworks under Copyright Law and constituted a legal person’s work conducted by the plaintiff andawarded 1500 RMB damages in the judgement which is now in force.
I do not completely agree with the court decision. The articles were written by AI. As mentionedabove, works created by non-natural persons, whether original or not, should not be protectedby copyright. The decision was made over three years ago. Works created by AI were rare, so itwas all right to protect them at that time. With the advent of ChatGPT and different kinds of AIsoftware, there are now so many articles, works of fine art, videos, music and apps created by AI.If a similar case arises now, the court would not decide in that way.
The audience may ask what if someone infringes rights in the articles that are not copyrightable.
Other NEWS

Information
- DeBund Law Offices
- Adresse: 8F Azia Center, 1233 Lujiazui Ring Road, Pudong New Area,Shanghai 200120, P.R.China.
- 沪ICP备11026599号-1
Contact us
- Tel.:8621-52134900
- Fax:8621-52134911
- Email:info@debund.com
- Supported by Shiyi Network S&T Co.,Ltd
Practices
 沪公网安备 31010602001694号
沪公网安备 31010602001694号